
Thoughtful MCP Server Design
What we can learn from BioMCP's 'think' tool and why persona-driven servers outperform generic ones

Last week, I needed to quickly learn about a few specific Active Pharmaceutical Ingredients (APIs). (As an example, acetaminophen is the API in Tylenol.) Once I got over my initial confusion that API ≠ Application Programming Interface, I asked Claude to help me research.
The results were good, but not great.
I was looking for details on regulatory filings, clinical trials, and licensing, but Claude’s web search results were mostly consumer-oriented - more WebMD than FDA.
Finding the right MCP Server
The problem here wasn’t the model, it was the data. So naturally, I went looking for a relevant MCP server.1 I searched on PulseMCP and quickly encountered BioMCP:

This is the promise of MCP servers: Instead of hoping the information you need is in the LLM’s training data or the top ten search results, you can connect your AI tool directly to structured, trusted datasets.
With BioMCP, Claude could now query data from ClinicalTrials.gov, PubMed, MyVariant.info, and cBioPortal, sites that are core to biomedical research.
What made BioMCP Stand Out
When I tried out BioMCP, I found two things about it to be fairly unique and interesting compared to other MCP servers I’ve used.
1. It’s designed for a persona, not a tool
Most MCP servers map one-to-one with a specific tool or dataset—Notion’s MCP server, S&P Global’s MCP server, the filesystem server for local files, and so on.
BioMCP, on the other hand, is persona-based. Rather than wrap one site, it’s designed to serve biomedical researchers, aggregating multiple high-quality sources into one interface. That made it much more effective than trying to find and connect to each site individually.
Other persona-based servers are also gaining traction. Context7, for example, is very popular among software engineers because it centralizes docs across hundreds of dev tools. And in the wake of Claude for Finance, we’re seeing lots of MCP-servers-for-finance-professionals emerge, like:
Financial Datasets (broad market data access, but at a steep price tag of $199/mo)
Composer MCP (backtests and execute trading strategies)
While I’m personally not yet ready to let an LLM trade stocks for me, I think we’ll continue to see more and more MCP servers like these ones: focused on providing all the tools and data that a specific persona needs to do their job.
Move over, Vertical SaaS! Vertical MCP servers have arrived!
2. BioMCP thinks before it acts
Another surprise: BioMCP doesn’t immediately fetch data when you submit a query. First, it thinks:
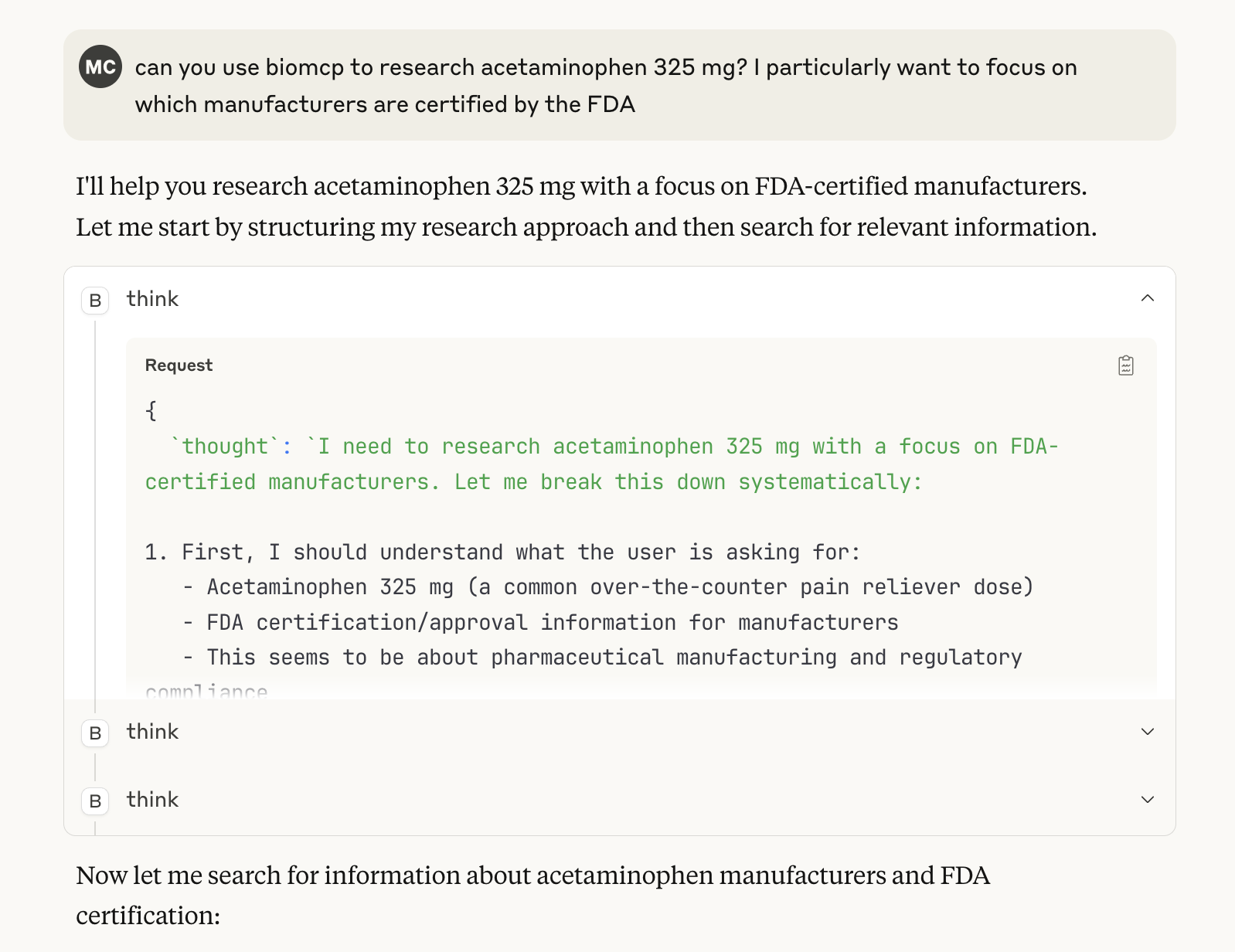
When I asked it to research Tylenol, the first few steps involved planning—not searching. Claude paused to figure out which sources to use, what order to call tools in, and what subtopics to investigate.
By the third thought, it had built a game plan. Only then did it query the appropriate tools, like article_searcher:
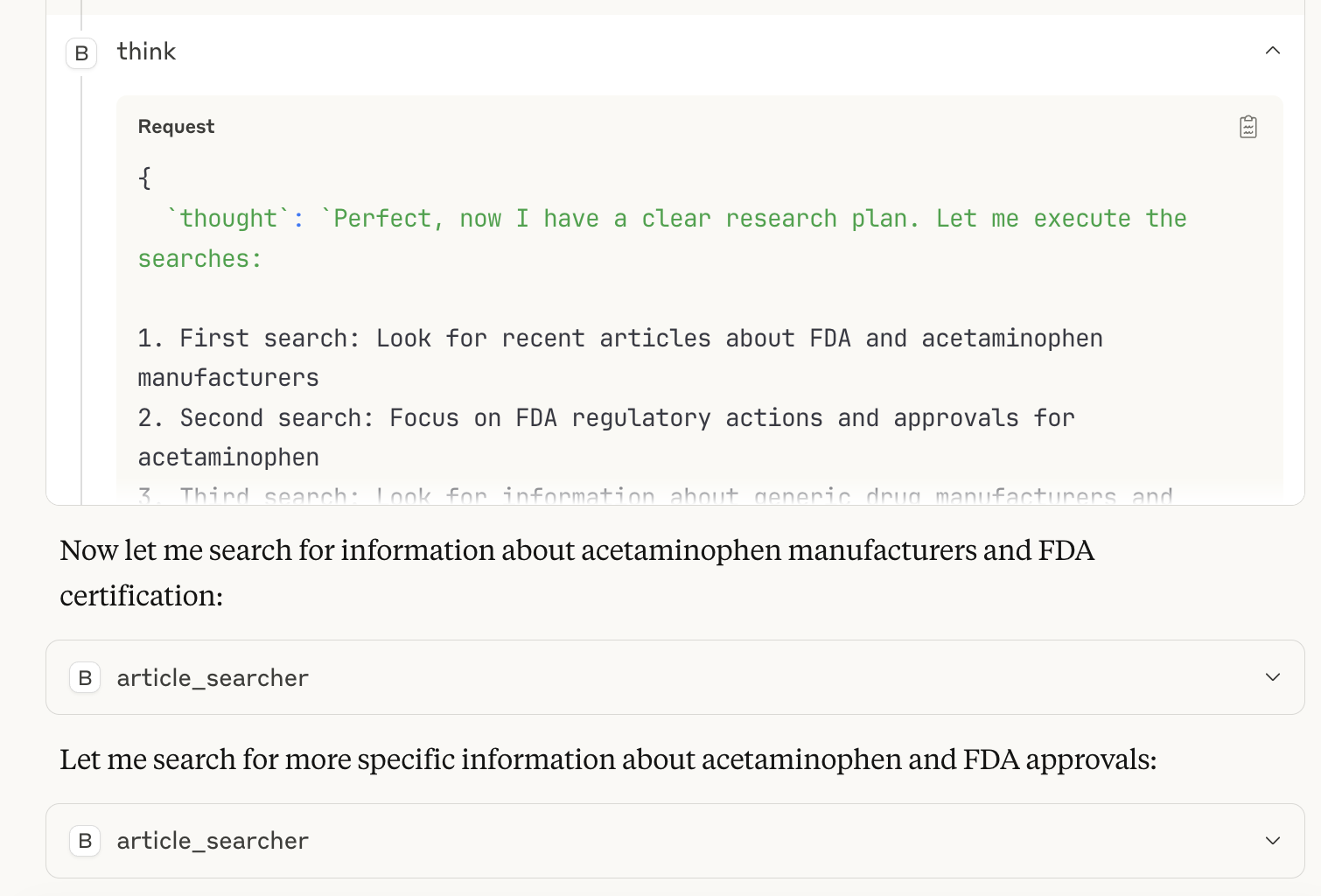
It was a an unusual approach, but it produced a solid report! When I dug into it more, I learned that this behavior was inspired by one of the earliest MCP servers: Sequential Thinking.
Being Very Late to the Party
Sequential Thinking was one of Anthropic’s original MCP servers, Sequential Thinking, released only a few days after the Model Context Protocol itself was introduced. I’m not sure why I never tried it out, but I’m distinctly late to the party.
The basis for how Sequential Thinking works (and why it works) lies in a technique called “Chain of Thought prompting”.
A Brief History of Chain of Thought (CoT)
In January 2022, Wei et al showed that asking LLMs to explain their reasoning significantly improved their ability to solve complex problems. This approach, dubbed Chain of Thought prompting, was typically done via few-shot examples (solved problems that the LLM could mimic):
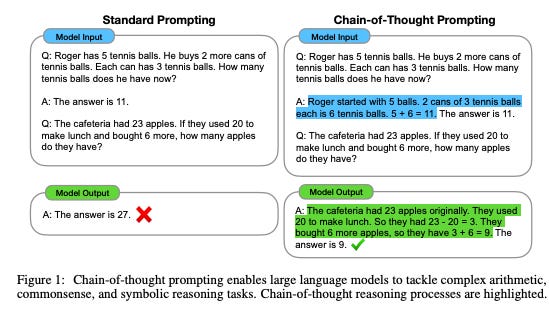
By following the ‘template’ from the examples, the LLM ended up writing out the logical progression, and often demonstrating better success.
Soon after, in May 2022, Kojima et al extended this to ‘Zero Shot Chain of Thought Prompting.’ In other words, Kojimat hat even without examples, adding the phrase “Let’s think step by step” was enough to trigger better reasoning:
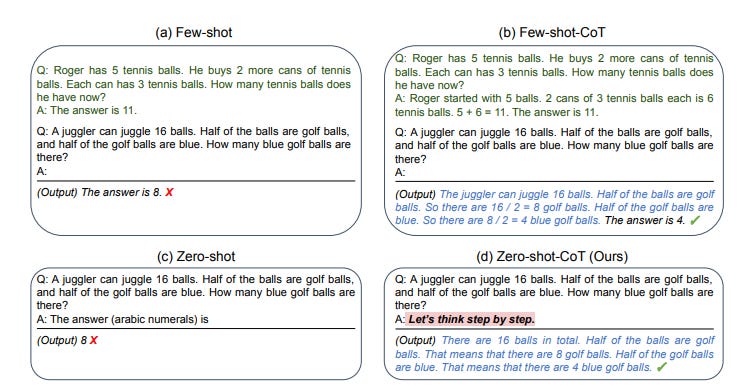
More than two years later, in late 2024, OpenAI released o1, a model that was actually trained (using reinforcement learning) to be good at complex reasoning tasks, in part by thinking step by step. Reasoning models no longer needed special prompting (and sometimes it even hinders performance); they naturally thought through problems as part of their behavior:

In other words, Chain-of-Thought was so successful, that it’s actually been more or less internalized into some models.
So is Sequential Thinking obsolete?
Not really, at least yet.
While reasoning models like o1 (and Claude Sonnet 3.7 a ‘hybrid reasoning model’, released in early 2025) reduce the need for Sequential Thinking as a separate MCP server, access to those models is still rate-limited for most users.
As a result, Sequential Thinking is still useful when you’re hoping to maximize output from a non-reasoning model like GPT-4o on a complex task.
It also can be useful when you want more control over the reasoning pathway (e.g. ability to control the number of thoughts, ability to branch or revise thinking steps):

Eventually, Sequential Thinking shouldn’t need to be an MCP server. Instead, MCP clients (e.g. ChatGPT, or Cursor) should be smart enough to automatically route complex reasoning queries to reasoning models, and route easier tasks to smaller models to save bandwidth. Cursor offers this today, but ChatGPT, for example, does not yet.
So one day, hopefully, if MCP clients evolve, the BioMCP think tool might be obsolete.
But in the meantime, I thought BioMCP’s decision to bake in a planning phase was pretty clever. It helped the server route queries to the right tools and extract more relevant insights. And in my case, it made sure I got the FDA data that I needed for my report.
Zooming out: Designing for Humans AND Models
Anthropic’s MCP Product Manager likes to remind folks that MCP servers actually have three users:
The MCP Client (e.g. ChatGPT, Cursor, Claude)
The LLM (e.g. 4-o, Sonnet 3.7)
The end user (e.g. me, you)
This is a lot of stakeholders, and it makes MCP design really difficult.
However, one of the most important lessons from BioMCP is that designing good MCP servers requires starting from human workflows.
The best MCP servers aren’t just wrappers around existing APIs or datasets. They’re built for specific people doing specific jobs, and they bring together the tools and data needed to execute those workflows smoothly.
And then, the best of the best are not just human end-user friendly, but also model- and context- friendly, ensuring that they provide the model the information it needs to execute that human workflow, and no more.
If you’re interested in further reading on MCP server design, a few pieces I would recommend:
Block’s guide to MCP server design: Detailed technical guidance, but written with a user centric lens.
From APIs to AI First Interfaces: Focused on how to design MCP servers that work well with the model
Notion’s rewrite of their MCP server: Highlights the changes that Notion made from v1 to v2. Notion MCP v1 was just a wrapper around existing APIs; v2 was redesigned from the ground up with users in mind.
And if you’ve seen any MCP servers whose design you find interesting or inspiring, let me know! Would love to try them out.
We really, really need better ways to discover and add relevant MCP servers from directly within the AI tools themselves. The team behind PulseMCP is actually working on developing the MCP server registry, which will be a key enabler for this.