
Crossing the MCP Adoption Chasm, Part I: Ease of Setup
Why configuring MCP servers is so painful — and what’s changing to fix it

If you’ve tried to set up an MCP server, you already know: it’s not easy.
In fact, I’d argue that ease of setup is the single biggest issue holding MCP back from mass adoption. It’s one of three major barriers that I outlined in my last post (alongside trust and monetization):

This is a shame, because MCP servers are really powerful. They let LLMs interact with tools, inject live context, and get things done in the real world. But right now, all that power is locked behind a setup process that’s clunky even for developers.
Let’s talk about where we are, what’s improving, and what needs to happen next.
Local First: The Developer Default
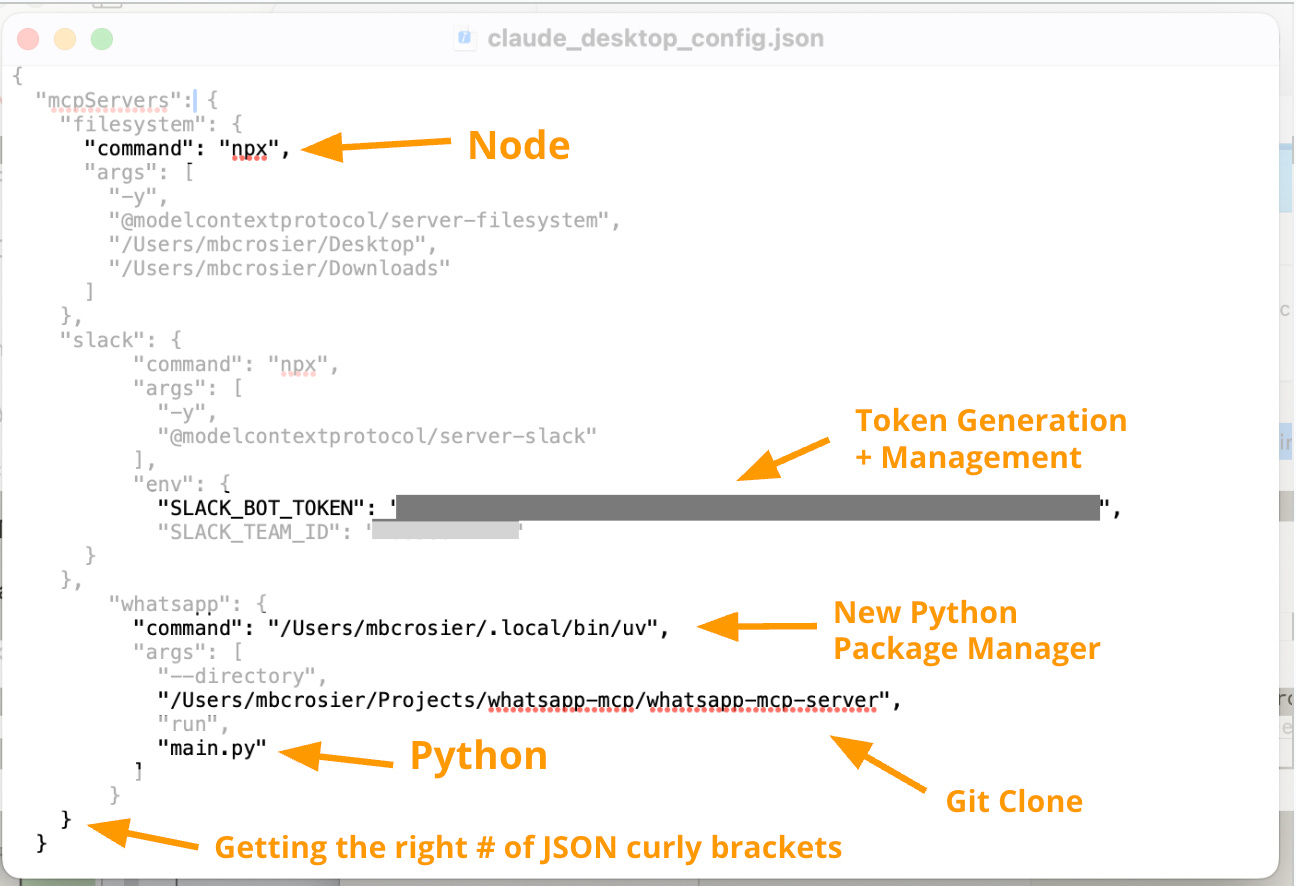
Today, most MCP servers are configured locally. That requires:
Cloning the server repo from GitHub
Installing dependencies (Node, Go, Python, package managers, etc.)
Generating and storing tokens
Adding info to a JSON config file inside your client app (e.g. Claude Desktop, Cursor)
Even as someone who considers myself semi-technical, I find this process frustrating.
Each time I set up a new MCP server, I encounter a new issue. I have pip installed, but not uv. I forget to cd into the right folder. I hit weird dependency issues. Each MCP server has unique requirements:
You have to be very motivated to get through it, which is fine for early adopters, but not for crossing the chasm — particularly when users may not fully understand the ‘why’ of MCP yet.
Where It’s Getting Better: Remote Access & OAuth
The good news? We’re already seeing real progress.
The Model Context Protocol’s creators and maintainers are hard at work addressing a few of the biggest pain points preventing this from be as easy and seamless as it one day should be.
Authentication and Authorization
One of the root causes of today's setup pain is that the original MCP spec didn’t include authentication or authorization. Some quick definitions:
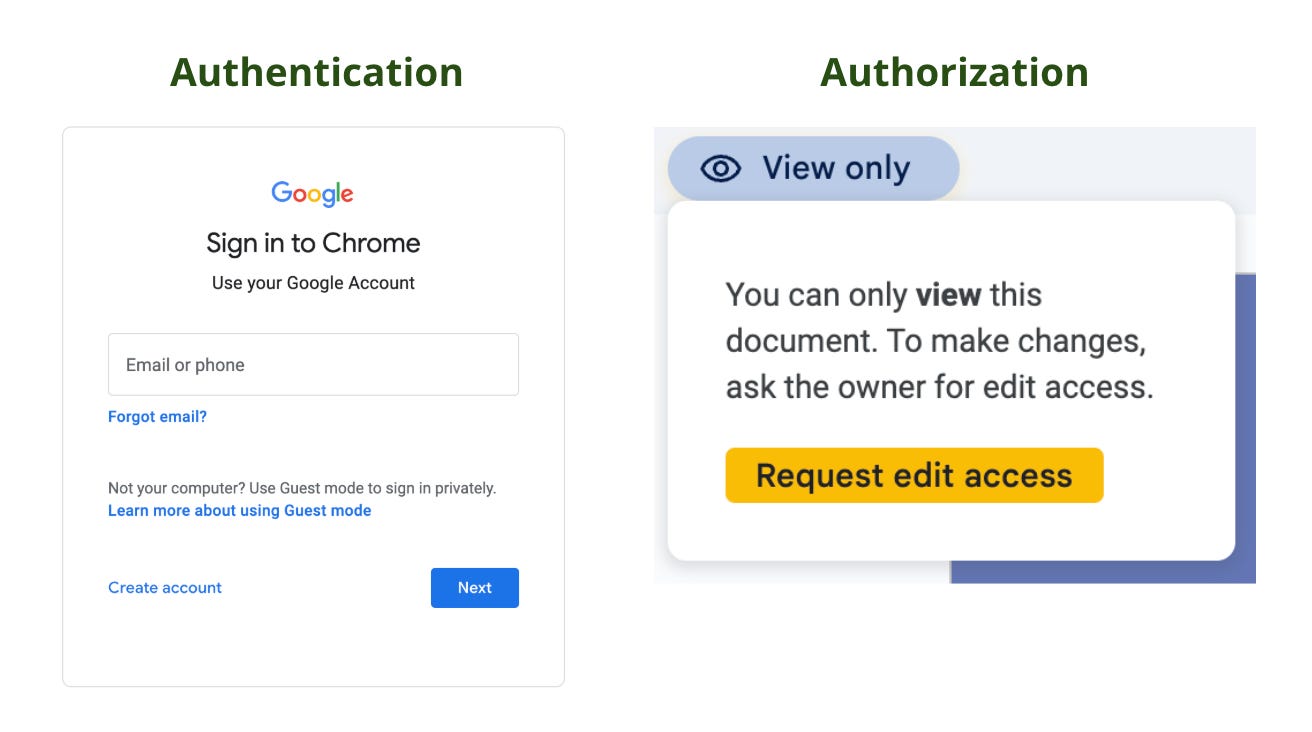
Authentication proves that you are who you say you are.
Authorization determines what you’re allowed to do, based on who you are.
For example, with Google Docs, you first log in with your Google account (authentication). Once signed in, your ability to view, comment, or edit a document depends on the access rights that have been granted to you (authorization):
Because early MCP implementations did not include these built-in security checks, they struggled to establish a secure and trusted connection. The simplest solution was to clone the MCP server locally (on your own computer) rather than trying to secure connections over the internet.
Transport: Moving from Local to Remote
To understand why this matters, let’s talk about transport. “Transport” refers to how data is moved from one place to another, in this case, between the language model (such as Claude Desktop) and the MCP server.
Currently, MCP supports three transport methods:
stdio (standard input/output) — Works only on your local computer
SSE (server-sent events) — Works over the internet (remote)
Streaming HTTP — Works over the internet (remote)
All three methods move data, but they do it in different ways.
Local Transport (stdio):
This method works only within your computer, where the operating system already trusts everything. There’s no need for extra identity checks because the computer trusts itself!
A local MCP server is designed to work with one client at a time, which fits the early MCP models that didn’t include authentication.
Remote Transports (SSE, HTTP):
When data is sent over the internet, the same inherent trust isn’t present. These methods need to include extra security measures like authentication and access control to ensure that only the right people can connect.
The advantage is that you don’t have to run the server on your local computer. Remote MCP servers can support many users at once in a secure way.

Right now, most early MCP server implementations have been local using stdio for transport, due to the limitations on authentication and authorization. However, as MCP’s auth support matures, remote MCP servers are likely to overtake local implementations.
A Quick Timeline
Here’s how we got here
Nov 5, 2024: MCP is introduced
Mar 26, 2025: Authorization is added to the spec; Cloudflare releases tooling for secure remote MCP servers
Late March: Community members pushed back on the initial implementation of authorization
Mid-April: Revised authorization proposals are now undergoing a RFC (Request for Comment) period and should be added to the MCP spec soon
This is all good news: it means secure, hosted MCPs are coming, and local setup will soon no longer be required for users to get started.
Imagining the Future: Setup That Just Works
Here’s the experience we should aim for:
You click “Enable Google Drive MCP”
A familiar login popup appears
You grant access to specific folders or actions
You’re in — and your LLM can now interact with your Google Docs
No tokens, no terminal, no JSON. This is the world that OAuth support makes possible — and the one that mass adoption will require.
Beyond Setup: Designing Better Clients
Improving security and connectivity is only part of the challenge. A big part of the experience is making it easy and pleasant for users to find and work with MCP servers. This means designing clients (the user interfaces that interact with these servers) to be simple, intuitive, and informative.
Ideas for better client design include:
Easy Discovery:
A searchable interface that lets you browse available MCP servers right from your language model client.Quick Insights:
At-a-glance ratings, developer information, and trust indicators so you know which servers are reliable and suitable for your needs.Simple Controls:
One-click options for enabling or disabling tools and the ability to choose which MCP server is used for a particular task.Transparent Costs:
Clear billing information that shows which services are free and which are paid.Streamlined Setup:
Reducing the number of steps to get started—like avoiding extra account setups or extra steps to generate API tokens—so you can begin using new tools quickly.
Many teams are tackling these challenges, from well-known companies to smaller, homegrown projects. Although progress has been made, there’s still room for improvement before we reach that "magical" experience.
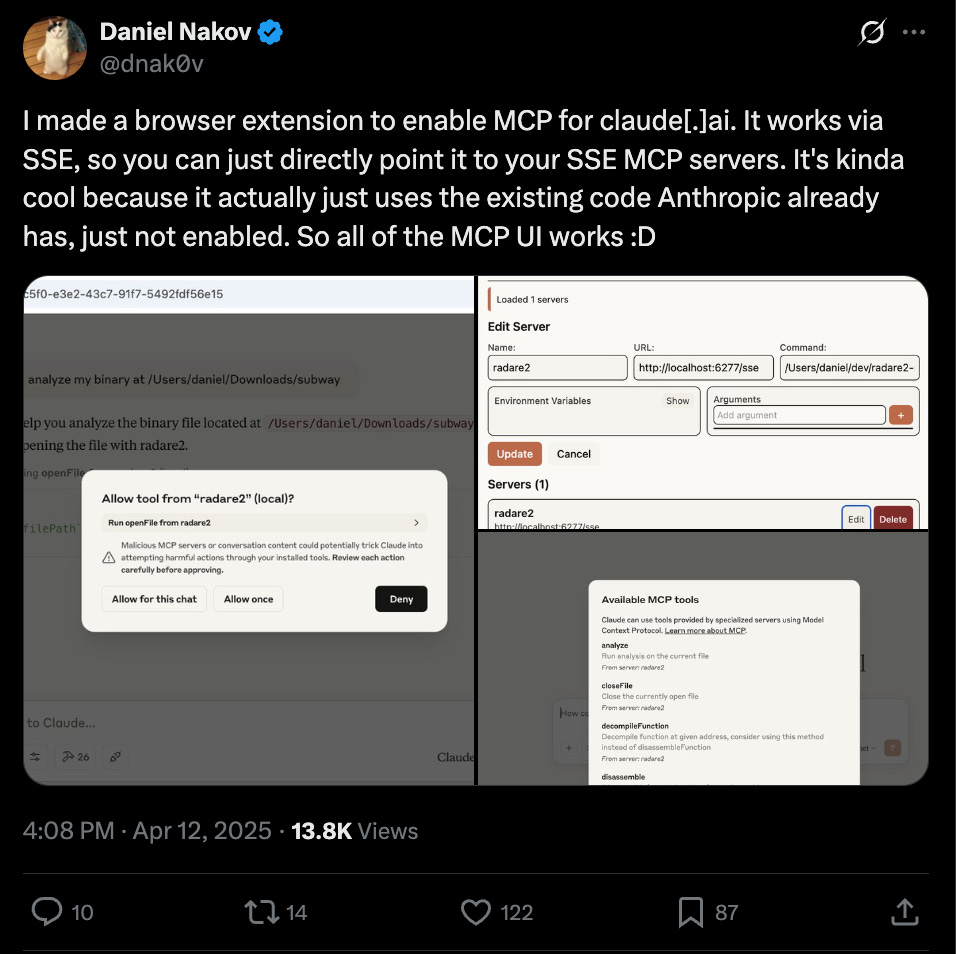
I’m personally intrigued to see if Anthropic will continue to lead in this area. Users have noticed that MCP support is available in Claude.ai, but just hidden. This indicates that Claude’s browser version could support remote MCP access sooner vs. later, setting the bar for future implementations:
We’re Close, But Not There Yet
The Model Context Protocol is a powerful standard, the tools are real, and the demos are very cool. But setup is still a bottleneck.
Until we make it easy to use, safe to trust, and simple to explore, MCP will remain a developer-focused tool, rather than a mass-adopted protocol.
The good news is that lots of the building blocks are already here or on their way — remote transport, OAuth, new client experiences.
Whoever puts these all together in a way that’s smooth enough for non-technical users to start to benefit from MCP has a lot to gain.
Up Next
In the next post, I’ll talk about what I see as the second big blocker to MCP adoption: Trust — and why we need better ways to vet and feel confident using MCP servers.