
Context Rot, or Too Much of a Good Thing
How AI performance degrades with lots of context, and how to manage context effectively when using MCP servers

A few months ago, a poster on Hacker News (a tech news forum) coined a new term: Context Rot.
“They [LLMs] poison their own context. Maybe you can call it context rot, where as context grows and especially if it grows with lots of distractions and dead ends, the output quality falls off rapidly.” - Workaccount2
What is Context Rot?
In other words, Context Rot is a way of saying that there can be too much of a good thing! If an LLM has too much context, it actually hurts model performance.
While people have known that this was true anecdotally for quite some time, Context Rot finally gives this phenomenon a name (inspired by the term “brain rot,” which is basically when your human brain stops functioning because you’ve spent too long on TikTok, or, reading Substack newsletters).
What does Context Rot mean for MCP?
“Context Rot” is a very interesting concept in the context (ha) of MCP servers.
If we go back to the “why” of MCP, MCP matters because often LLMs don’t have the right context or enough context. The Model Context Protocol is an open protocol that allows LLMs to connect to different data sources in a standardized way. In doing so, it gives the LLM more context from third party sources so it has the information and tools it needs to succeed.
But, if MCP servers are poorly designed or poorly used, they can end up providing so much context that model performance gets worse, not better.
In this post, we’ll cover how context works in LLMs, what happens when it gets too big, and what each member of the MCP ecosystem (from users to toolmakers) can do to keep models effective.
First: What Even Is Context?
Every large language model (LLM) has a specified context window, which is basically the model’s short-term memory. It's the information the model has ‘on hand’ to understand your specific question or task.
This includes your prompt, any files you upload, the data that the model pulls in from web searches or from the output of MCP server tools, and your conversation history within a given chat. All of that data is then the context. The LLM then chops up all of your context into tokens:

Tokens are chunks of text that the LLM that are small enough for the LLM to represent as numbers for processing. You can visualize how any sentence or piece of text gets split up into tokens using a tool like TikTokenizer.
In the sentence above, “Sentences” gets split into two tokens, [Sent][ences], while [ like] is its own token (including the space at the beginning).
A model’s context window is basically the maximum possible number of tokens it can process, so models with larger context windows can handle longer prompts, file uploads, and chat conversations.
Context Windows on the Rise 📈
In early iterations of LLMs, context windows were small. You couldn’t feed ChatGPT a ton of files, or ask Claude to review big chunks of your codebase. But as models have improved and infrastructure scaled, context windows have gotten bigger and bigger.
Here’s a chart, made by Gemini (so, take it with a grain of salt), showing the context window sizes for several popular models today:
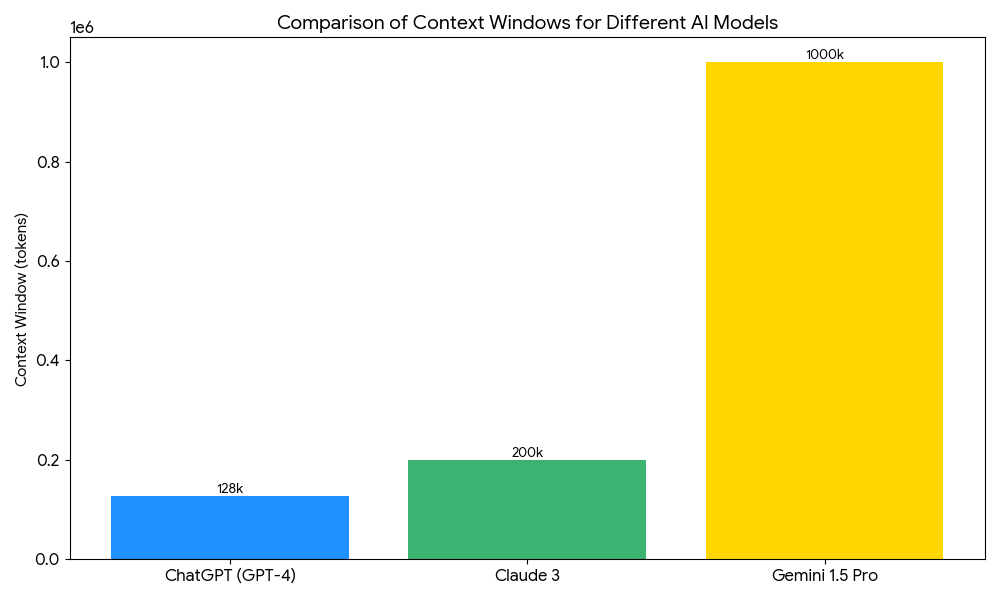
To help conceptualize these numbers, a typical token is ~0.75 of a word, so ChatGPT’s 128,000 token context window (the lowest value on this chart) is comparable to putting a 200 page book into working memory.
As you can see, Google in particular has pushed the envelope on context windows, offering multi-million-token windows at very low costs (it helps to own your own infrastructure, namely Google Cloud Platform).
While these seem like really big numbers, they actually aren’t that big. If you’re regularly processing big documents (think: spec sheets, legal filings, consulting powerpoint decks), keeping chat conversations going for a long time, or heavily using MCP tools, you’re probably going to hit the limits, particularly for ChatGPT and Claude. And then, maybe you’ll join the folks rallying for longer Context Windows in the ChatGPT forum.
But, while larger context windows open up new use cases and avoid annoying error messages, there are clearly demonstrated limits to the “more is more” approach.
Enter: Context Rot
While longer context windows in themselves are not a problem, when we start to add too much context, LLMs perform worse.
As evidence, Chroma put out a research piece on Context Rot a few weeks ago, demonstrating how LLM reliability drops off with longer inputs across a few different experiments.
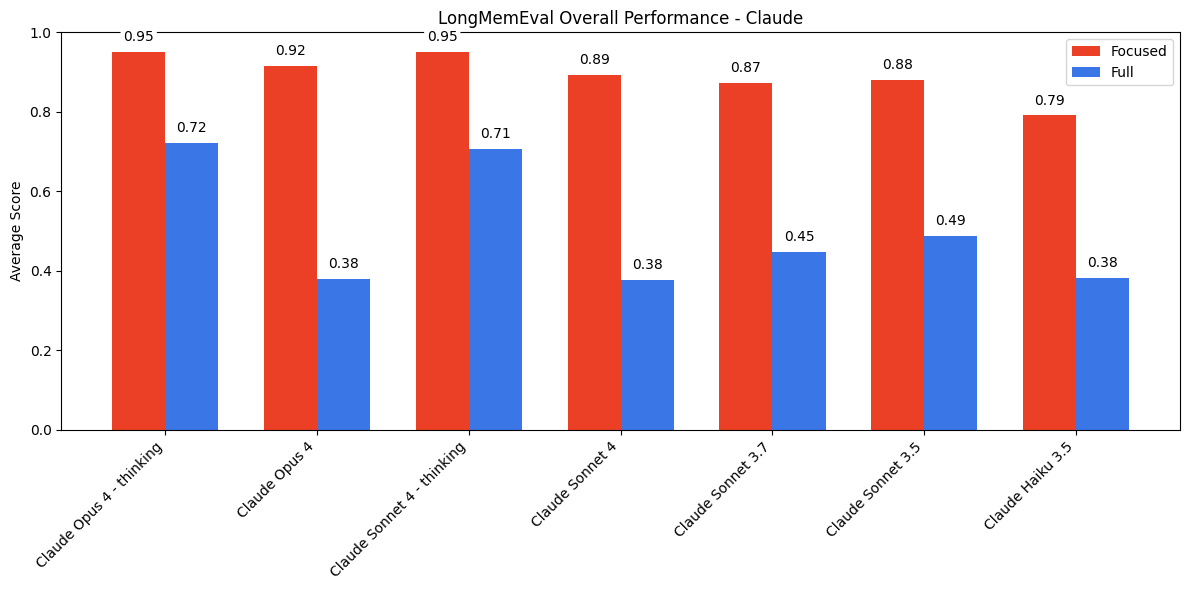
For example, in their LongMemEval experiment, they compared model results with a focused (~300 token) input vs. with a less-focused, longer (~113k token) input, where the less focused input is attempting to mimic having a very long chat conversation or uploading a bunch of documents.
Unsurprisingly, we see context rot in action - models like Claude perform much better on the focused input than on the full input (and reasoning models outperform non-reasoning models):
There’s lots of other research that demonstrates this phenomenon; for example, Liu et al showed that when there’s a lot of context, models do better at “remembering” details from the beginning and end of the context.
When the researchers uploaded 20 documents and asked the model specific questions about them, the model was far more accurate in answering questions about the first document and the 20th document than the 10th:
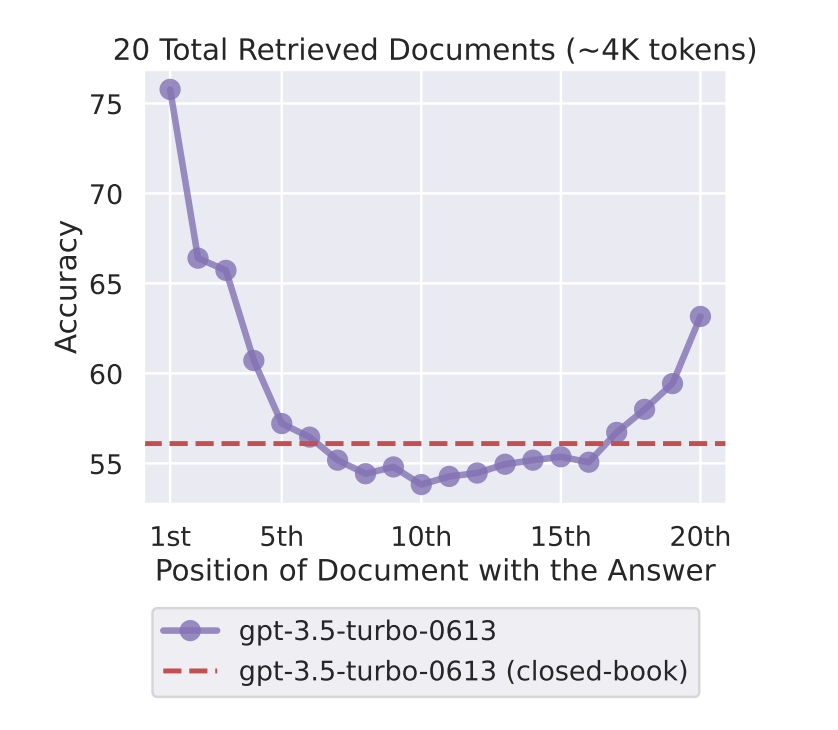
In other words, information literally gets lost in the middle — context rot in action.
What This Means for the Model Context Protocol
Now that our definitions are clear, let’s return to the implications for MCP!
MCP servers let you do amazing things, like search Gmail for conversation history so that Claude can write better email drafts, and query your database to return raw data for analysis. But it achieves all of that by adding lots of context from third party tools. So the natural question becomes: how much context is too much?
While there’s no precise answer, there are lots of actionable things that each player in the MCP ecosystem can do to help preserve context, or practice context-aware design. I’ll run through a few examples, but there are probably lots more out there (please let me know what I missed!).
Quick Reminder: MCP Roles & Responsibilities
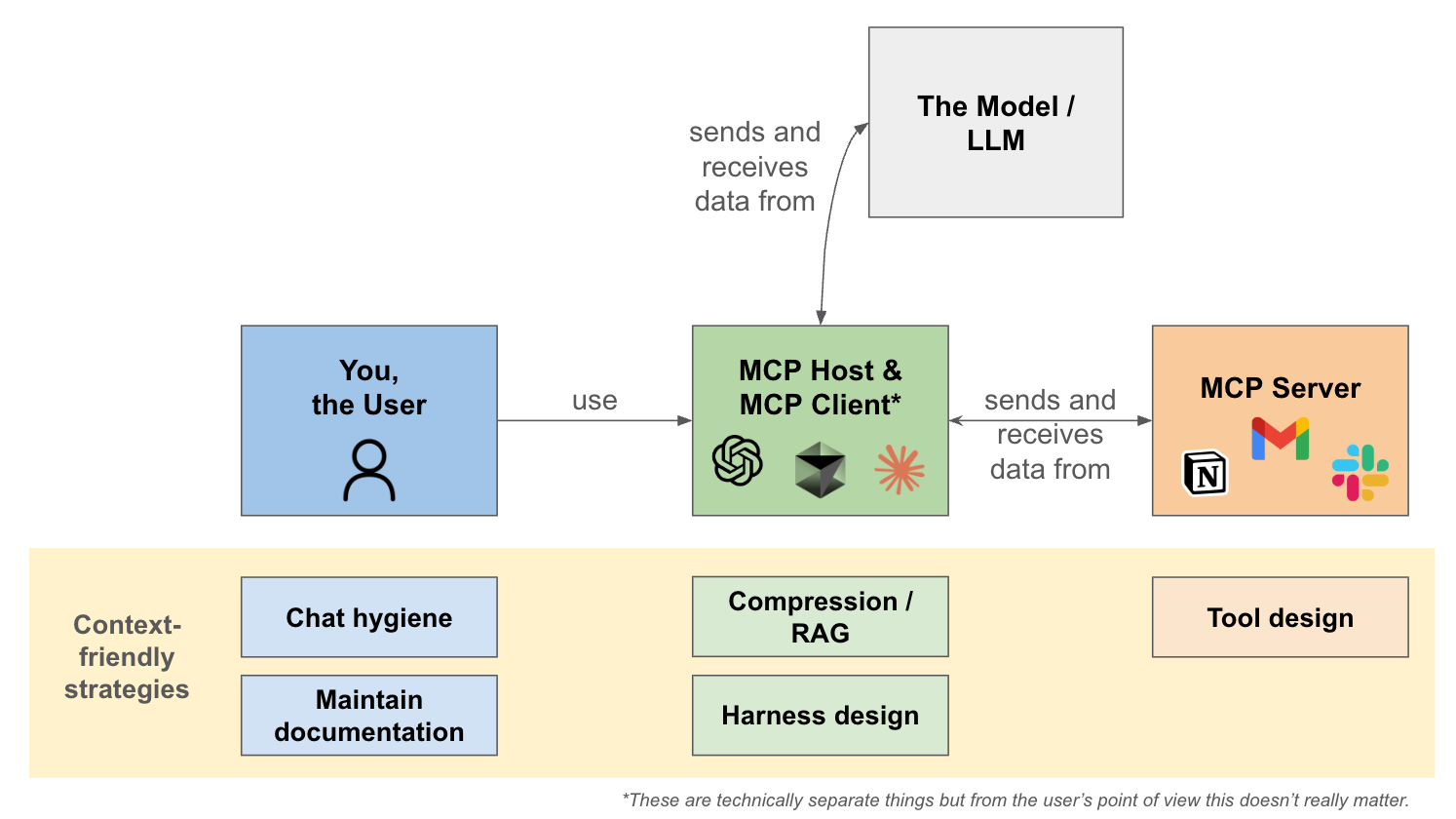
Let’s quickly remember who all the different players are in our MCP ecosystem.
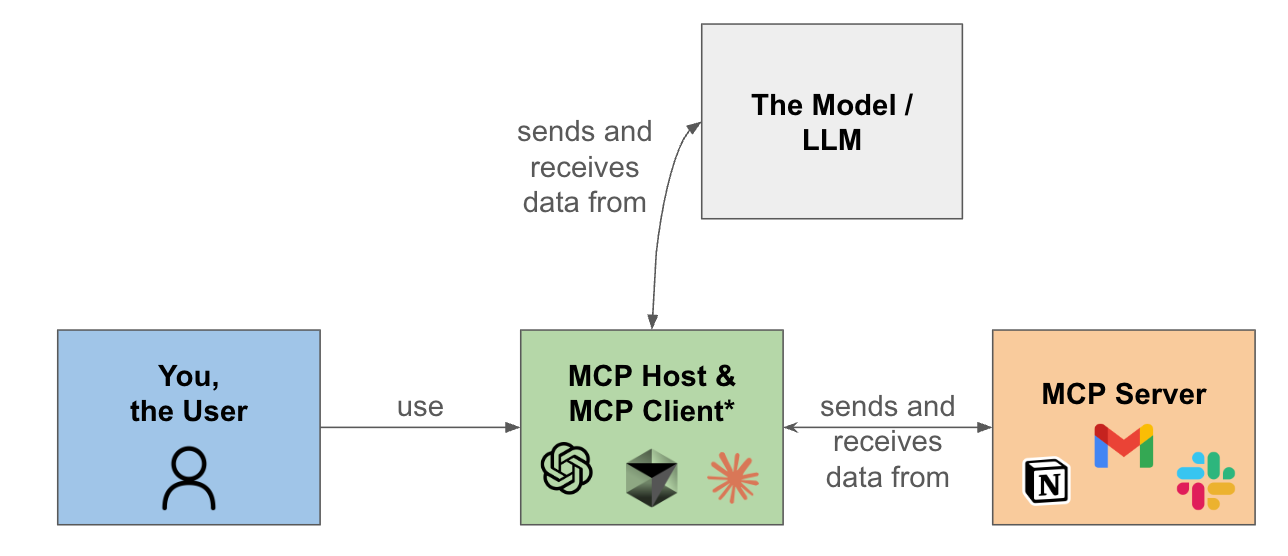
First there’s you, the User.
You interact with the MCP Host or Client (*technically distinct, but functionally similar from your perspective). This is the interface you use to access AI models. Examples of MCP Clients include ChatGPT, Cursor, or Claude Code. The Host/Client decides when and how to invoke MCP servers, based on the needs of the task and the judgment of the Model.
MCP servers, such as Slack, Notion, or Gmail, expose specific tools, prompts, or resources that the Host/Client can call to gather relevant context or perform actions. These servers follow a standard protocol for structured interactions with models.
The MCP Host/Client then packages the retrieved context and serves it to the Model as part of its input. The Model processes this context, generates an output, and returns results to you, the User.
Preventing Context Rot across MCP
Across these roles, everyone has a job to play in avoiding context rot and using MCP servers effectively:
You, the User
There are a few strategies you can use personally as an end-user to manage context effectively and avoid context rot.
Chat Hygiene
The first is to keep a given chat or conversation on topic. If you ask ChatGPT in the same conversation thread to provide you with travel planning advice and then to help you research home furniture, you might get weird results. Mixing contexts makes the LLM less focused and less effective. And, as we saw in the study above, information can get lost in the middle
You can manage this by:
Starting a new chat whenever you switch topics or a conversation gets long
Using project folders in tools like ChatGPT to organize your chats and provide shared context to related but separate conversations.
Intentionally limiting how many big documents you upload in a single chat thread
Maintaining Documentation
Particularly for coding or in-depth research use cases, maintaining documentation and summarizing your progress provides a helpful way to carry over the most important context between chat sessions. You can either do this ad hoc or programmatically.
Ad hoc: When a chat is getting long and approaching its context window (so performance is degrading), you can ask the LLM to summarize the conversation, and then paste that summary into a new chat to start again with some existing context, but more focus.
Programmatically: You can maintain a project-specific documentation or summary file, and ensure the LLM always refers back to it.
For example, Anthropic highly recommends maintaining a claude.md file (basically, a text file with key project instructions) when using Claude Code. Claude Code automatically pulls in this file at the start of any conversation, so the knowledge it contains is always passed along to new chats.
MCP Client/Hosts
Harness Design (Orchestration/Tool Logic)
This one is newer to me, but the ‘harness’ is basically an overarching term for the logic that the MCP Client (e.g. the creators of Claude Code, or ChatGPT) builds in behind the scenes. That logic includes how the Client decides what MCP tools to use, and when.
To tie this to the example above, Claude Code’s harness dictates that at the start of each new chat, the LLM should read the claude.md file, if there’s one available. This helps users ensure that the things they care about most (and have documented in claude.md) persist across new chats, even if the User doesn’t actively remind the model of those detials.
While Claude Desktop and Claude Code are two different MCP Clients created by the same company, Anthropic, it’s generally agreed that Claude Code has the better ‘harness’ - so better logic for deciding how to use tools, chain actions, manage context, and more. As a result, Claude Code is better at using MCP servers thoughtfully and in a way that conserves context, by calling the right tools at the right time.
Context Compression
A sub-category within harness design is context compression. This is where the MCP Client automatically does the equivalent of you asking the LLM to summarize your existing chat, and then porting over that summary to a fresh window.
Here’s an example of what this looks like in Claude Code:
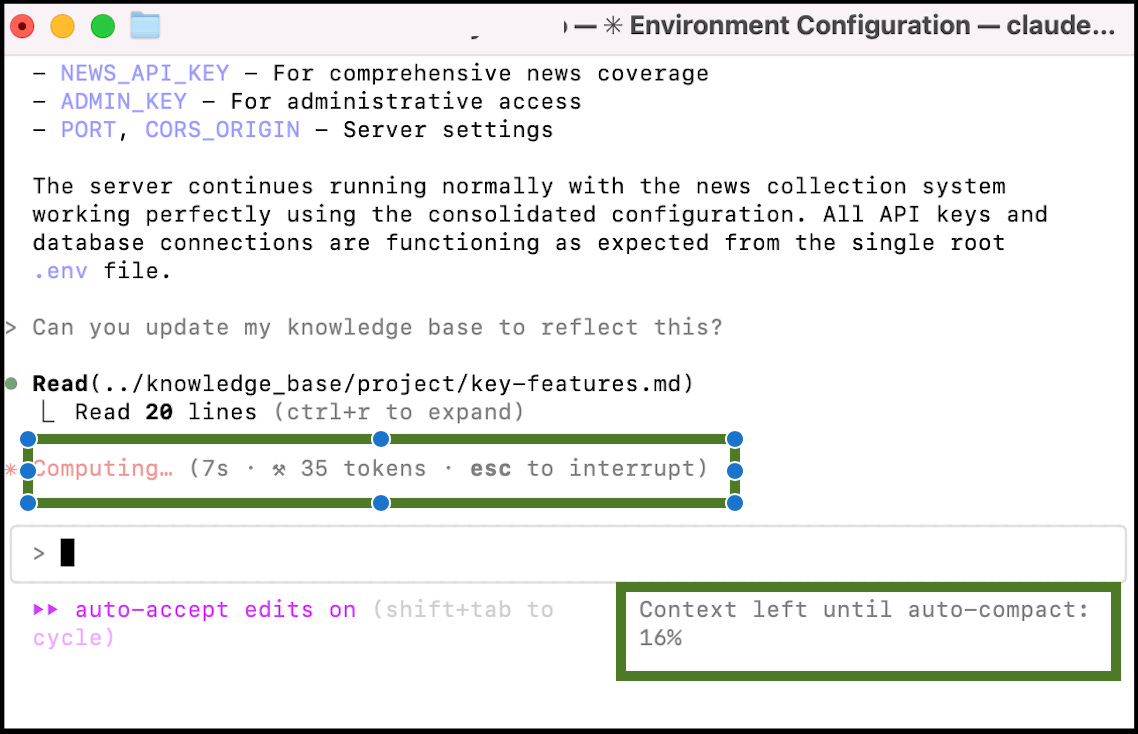
Since Claude Code is developer facing, it shows you a bit of what’s happening under the hood: how many tokens you’ve used, and when it’s planning to automatically compact the conversation. After compression, Claude Code then re-reads the key files (including claude.md) to ‘get itself back up to speed.’ While performance tends to be worse right after compression, it’s much better than if you let the conversation go on indefinitely and allow context rot to set in.
This is not unique to Claude Code. When Block went all-in on MCP internally, they quickly found that employees were hitting context limits by using tons of tools, so compression was one of the first features they had to add to their homegrown MCP Client, Goose.
Retrieval-Augmented Generation (RAG)
Another example of how companies tackle this is OpenAI’s approach to long documents. While I’ll caveat that the source here is Reddit, it’s generally believed that ChatGPT uses a tactic called RAG (Retrieval-Augmented Generation) to process long documents, rather than literally going through the document word by word and token by token.
This tactic is more context-efficient, because it allows the LLM to focus on parts of the text that may be relevant to your specific prompt or question, but may be less accurate if it results in key details being missed.
As with all things, there are tradeoffs!
MCP Server creators
Finally, the actual creators of MCP servers need to be thoughtful about tool design. I wrote about this in my last post on BioMCP, so won’t dwell much on it here, but a few examples of what this looks like in practice include:
Designing MCP server tools based on specific-user tasks, rather than around API endpoints
Returning the most relevant information, rather than the most information
A personal example of this phenomenon: Earlier this year, I created an MCP server for Canvas (my school learning platform). A given Canvas assignment has 92 fields that can be accessed via the API.
While the most comprehensive MCP server might return all 92, in practice, many of them simply aren’t relevant to me. I’ve quite literally never had a peer graded assignment, so returning the 5 fields related to that will only increase my context usage and likelihood of confusing the LLM.
In other words, the best MCP servers aren’t the ones that fetch everything. Instead, they’re the ones designed with context in mind.
In Summary: How to Avoid Context Rot (especially when using MCP Servers)
In summary, to avoid the effects of context rot:
Be thoughtful about what you include. Uploading the most important documents will likely get better results than uploading every document possible.
Manage context actively. Start a new chat when you’re switching tasks. And document your work as you go, particularly for big tasks like coding or research.
Choose MCP servers and clients with care. They aren’t all created equal!
Choose MCP servers designed for relevance, not comprehensiveness.
Well-designed MCP clients like Claude Code and Goose that compress context and have strong ‘tool harnesses’ make it easier to wield MCP servers effectively.
While context rot isn’t going away (at least in the near term), we can still get better at managing it by being thoughtful with what tools we use, and how we use them. After all, models, just like us, are forgetful sometimes!
Super interesting! I’ve run into the same issue building RAG apps, where even if chunks are technically “relevant,” too much context can confuse the model or dilute the answer. Would love to hear how you're approaching context filtering or ranking on your end!